



 数据结构 ?
20085.3M
数据结构 ?
20085.3M
 Data Structure ?
Data Structure ?

* 以上分析是由系统提取分析形成的结果,具体实际数据为准。
README.md
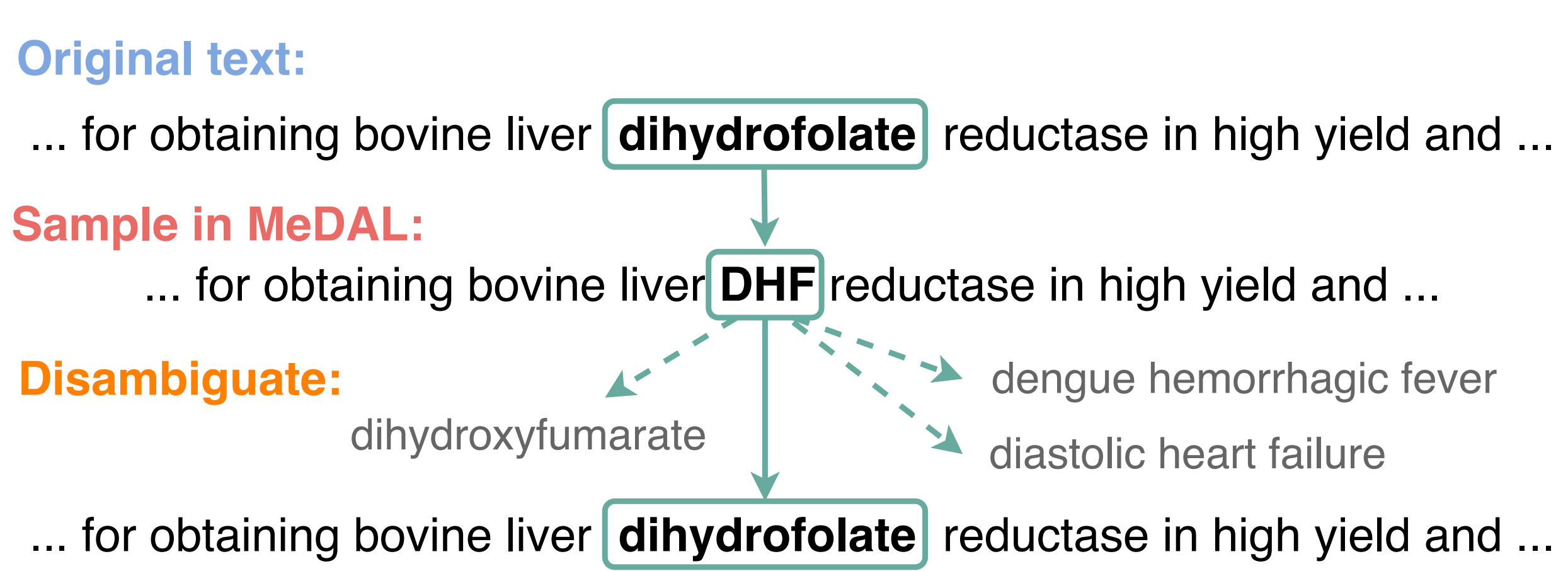
**Me**dical **D**ataset for **A**bbreviation Disambiguation for Natural **L**anguage Understanding (MeDAL) is a large medical text dataset curated for abbreviation disambiguation, designed for natural language understanding pre-training in the medical domain. It was published at the ClinicalNLP workshop at EMNLP.
?? [Code](https://github.com/BruceWen120/medal)
?? [Dataset (Hugging Face)](https://huggingface.co/datasets/medal)
?? [Dataset (Kaggle)](https://www.kaggle.com/xhlulu/medal-emnlp)
?? [Dataset (Zenodo)](https://zenodo.org/record/4265632)
?? [Paper (ACL)](https://www.aclweb.org/anthology/2020.clinicalnlp-1.15/)
?? [Paper (Arxiv)](https://arxiv.org/abs/2012.13978)
? [Pre-trained ELECTRA (Hugging Face)](https://huggingface.co/xhlu/electra-medal)
## Downloading the data
We recommend downloading from Kaggle if you can authenticate through their API. The advantage to Kaggle is that the data is compressed, so it will be faster to download. Links to the data can be found at the top of the readme.
First, you will need to create an account on kaggle.com. Afterwards, you will need to install the kaggle API:
pip install kaggle
Then, you will need to follow the [instructions here](https://github.com/Kaggle/kaggle-api#api-credentials) to add your username and key. Once that's done, you can run:
kaggle datasets download xhlulu/medal-emnlp
Now, unzip everything and place them inside the `data` directory:
unzip -nq crawl-300d-2M-subword.zip -d data
mv data/pretrain_sample/* data/
Loading FastText Embeddings
For the LSTM models, we will need to use the fastText embeddings. To do so, first download and extract the weights:
wget -nc -P data/ https://dl.fbaipublicfiles.com/fasttext/vectors-english/crawl-300d-2M-subword.zip
unzip -nq data/crawl-300d-2M-subword.zip -d data/
## Model Quickstart
Using Torch Hub
You can directly load LSTM and LSTM-SA with `torch.hub`:
python
import torch
lstm = torch.hub.load("BruceWen120/medal


暂无相关内容。
暂无相关内容。
- 分享你的想法
去分享你的想法~~
全部内容
欢迎交流分享
开始分享您的观点和意见,和大家一起交流分享.
数据使用声明:
- 1、该数据来自于互联网数据采集或服务商的提供,本平台为用户提供数据集的展示与浏览。
- 2、本平台仅作为数据集的基本信息展示、包括但不限于图像、文本、视频、音频等文件类型。
- 3、数据集基本信息来自数据原地址或数据提供方提供的信息,如数据集描述中有描述差异,请以数据原地址或服务商原地址为准。
- 1、本站中的所有数据集的版权都归属于原数据发布者或数据提供方所有。
- 1、如您需要转载本站数据,请保留原数据地址及相关版权声明。
- 1、如本站中的部分数据涉及侵权展示,请及时联系本站,我们会安排进行数据下线。
 VIP下载(最低0.24/天)
VIP下载(最低0.24/天) 279浏览
279浏览 0下载
0下载 0点赞
0点赞 收藏
收藏 分享
分享