



 数据结构 ?
14.45M
数据结构 ?
14.45M
 Data Structure ?
Data Structure ?

* 以上分析是由系统提取分析形成的结果,具体实际数据为准。
README.md
**Context** - These datasets were produced as part of a little research project I undertook for a blog post on sentiment analysis, which you can access here: https://bit.ly/32PmWdf - I uploaded a more extensive dataset of presidential speeches on Kaggle here: https://bit.ly/2E7Fmvw **Content** The datasets were created to compare sentiment scores across two text types (tweets versus political speeches) and three sentiment models (Pattern, Vader and the polarity model incorporated in Stanford CoreNLP). ***- sentiment_speeches_Kaggle.csv: *** The dataset contains sentiment codings (Pattern,Vader & Stanford model) for al inauguration and state of the union speeches of US presidents since 1917 on sentence level. **-sentiment_tweets°Kaggle.csv:** The dataset contains sentiment codings (Pattern,Vader & Stanford model) for a sample of around 11500 tweets of US politicians (Donald J. Trump (Rep.), Rand Paul (Rep.),Ted Cruz (Rep.), Alexandria Ocasio-Cortez (Dem.), Nancy Pelosi (Dem.) and Bernie Sanders (Dem.)). The sentiment polarity has been computed on tweet-level, not sentence-level. I simply scraped the last 2000-ish tweets of each timeline using the GetOldTweets module for Python. You can read more about the data collection process in the aforementioned blog post (https://bit.ly/32PmWdf). **Distribution of sentiment scores** 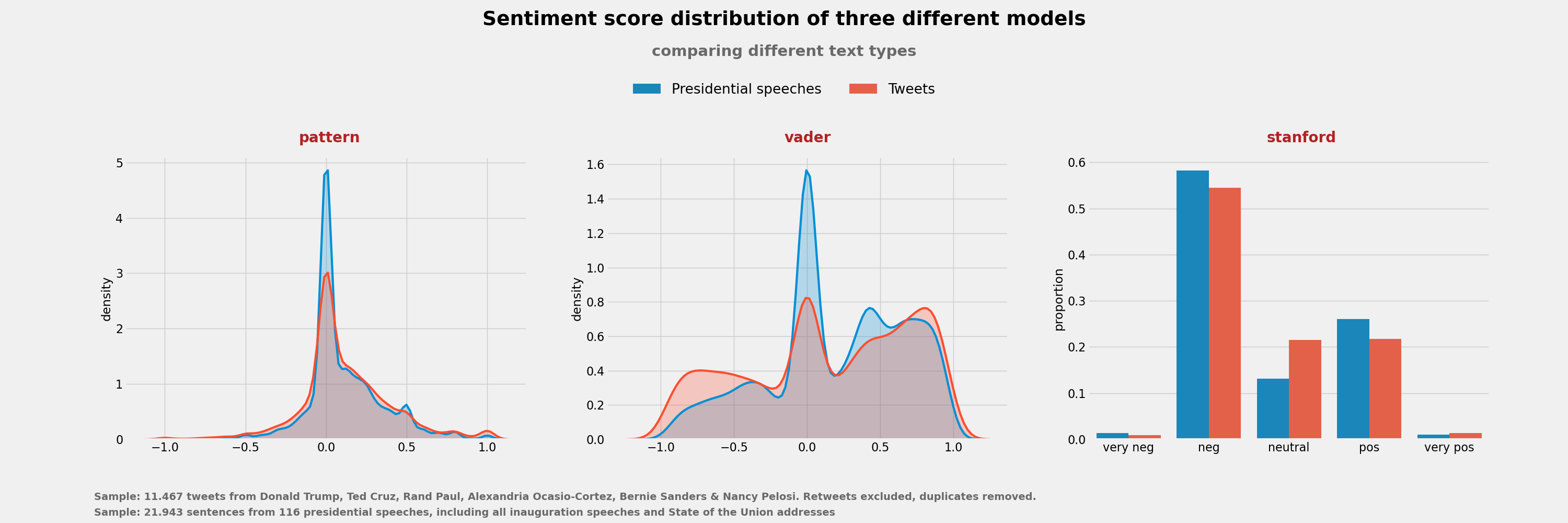 ** Some example analyses ** - The fact that the analyses of presidential speeches has been performed on sentence-level makes an analysis of polarity-development within the same text extremely easy. For example, one can easily plot the polarity scores across a single inaugural speech, like I did here for the inaugural addressees since JFK:  - One could also compare how these models code a particular tweet or speech and index the amount of (dis)agreement betwene the different models: 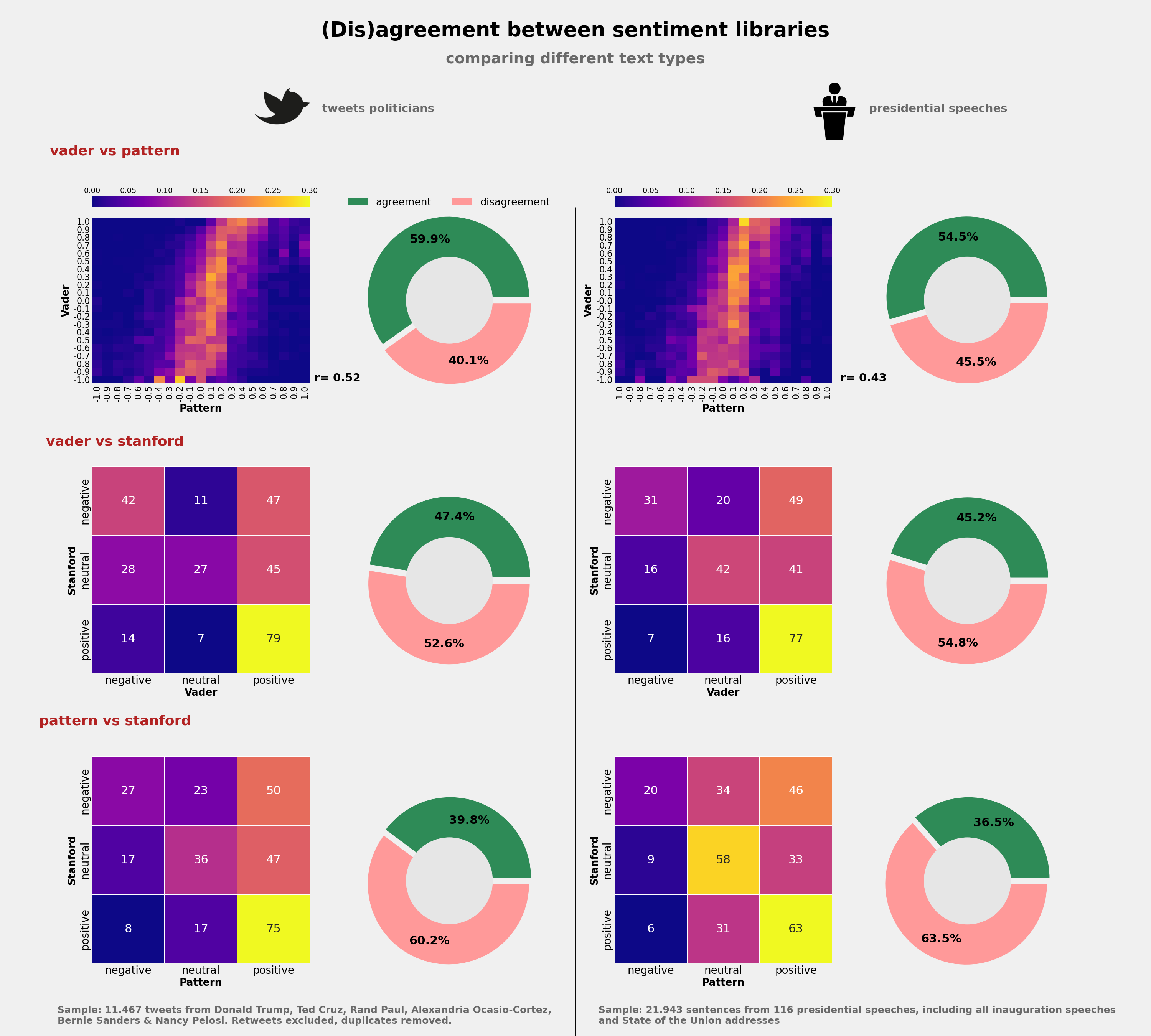 You can read more about the data collection, wrangling and analysis process in the aforementioned blog post.


- 分享你的想法
全部内容
数据使用声明:
- 1、该数据来自于互联网数据采集或服务商的提供,本平台为用户提供数据集的展示与浏览。
- 2、本平台仅作为数据集的基本信息展示、包括但不限于图像、文本、视频、音频等文件类型。
- 3、数据集基本信息来自数据原地址或数据提供方提供的信息,如数据集描述中有描述差异,请以数据原地址或服务商原地址为准。
- 1、本站中的所有数据集的版权都归属于原数据发布者或数据提供方所有。
- 1、如您需要转载本站数据,请保留原数据地址及相关版权声明。
- 1、如本站中的部分数据涉及侵权展示,请及时联系本站,我们会安排进行数据下线。
 VIP下载(最低0.24/天)
VIP下载(最低0.24/天) 693浏览
693浏览 1下载
1下载 0点赞
0点赞 收藏
收藏 分享
分享