



 数据结构 ?
10.3G
数据结构 ?
10.3G
 Data Structure ?
Data Structure ?

* 以上分析是由系统提取分析形成的结果,具体实际数据为准。
README.md
该双嵌入空间模型(DESM)是一个信息检索模型使用两个词的嵌入,一个查询词和一个文档的话。
它考虑了每个查询词向量与所有文档词向量之间的向量相似度。
信息检索的主要挑战是对文档的有关性进行建模。传统方法使用词频,出现更多查询词表示文档更可能与该词有关。DESM使用多个文档词作为每个查询词的关联性证据。例如,对于查询词“ Albuquerque”,以下两个文本段落根据词频无法区分,每个出现一次。我们的方法考虑了诸如“人口”和“都市”之类的相关术语的存在,这证明了段落(a)与阿尔伯克基有关,而段落(b)仅提及阿尔伯克基。

在这里,我们使用众所周知的工具word2vec生成双重嵌入。在大多数word2vec研究中,单词嵌入仅来自模型的输入矩阵(IN)。在本文中,我们还使用输出矩阵(OUT)嵌入。在下表中,“耶鲁”的IN向量与“哈佛”的IN向量(IN-IN)接近,但在OUT空间中,其最接近的邻居是“教师”(IN-OUT)。单一嵌入方法(IN-IN和OUT-OUT)倾向于将相同类型的词归为一组(典型),而双重嵌入方法(IN-OUT)将在训练数据中一起出现的词归为一组(局部)。
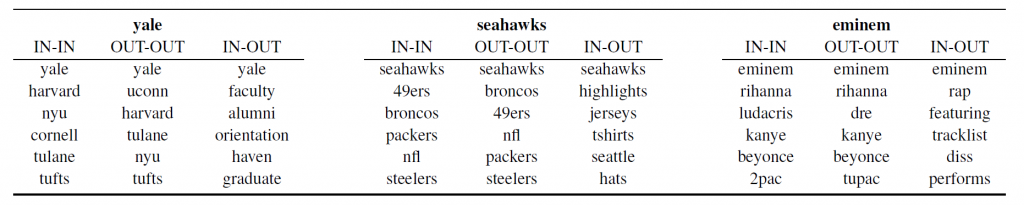
使用双重嵌入执行全对比较的DESM方法在信息检索测试平台上产生了积极的结果。


暂无相关内容。
暂无相关内容。
- 分享你的想法
去分享你的想法~~
全部内容
欢迎交流分享
开始分享您的观点和意见,和大家一起交流分享.
数据使用声明:
- 1、该数据来自于互联网数据采集或服务商的提供,本平台为用户提供数据集的展示与浏览。
- 2、本平台仅作为数据集的基本信息展示、包括但不限于图像、文本、视频、音频等文件类型。
- 3、数据集基本信息来自数据原地址或数据提供方提供的信息,如数据集描述中有描述差异,请以数据原地址或服务商原地址为准。
- 1、本站中的所有数据集的版权都归属于原数据发布者或数据提供方所有。
- 1、如您需要转载本站数据,请保留原数据地址及相关版权声明。
- 1、如本站中的部分数据涉及侵权展示,请及时联系本站,我们会安排进行数据下线。
 VIP下载(最低0.24/天)
VIP下载(最低0.24/天) 659浏览
659浏览 0下载
0下载 0点赞
0点赞 收藏
收藏 分享
分享