
公开数据集

 数据结构 ?
373.28M
数据结构 ?
373.28M
 Data Structure ?
Data Structure ?

* 以上分析是由系统提取分析形成的结果,具体实际数据为准。
README.md
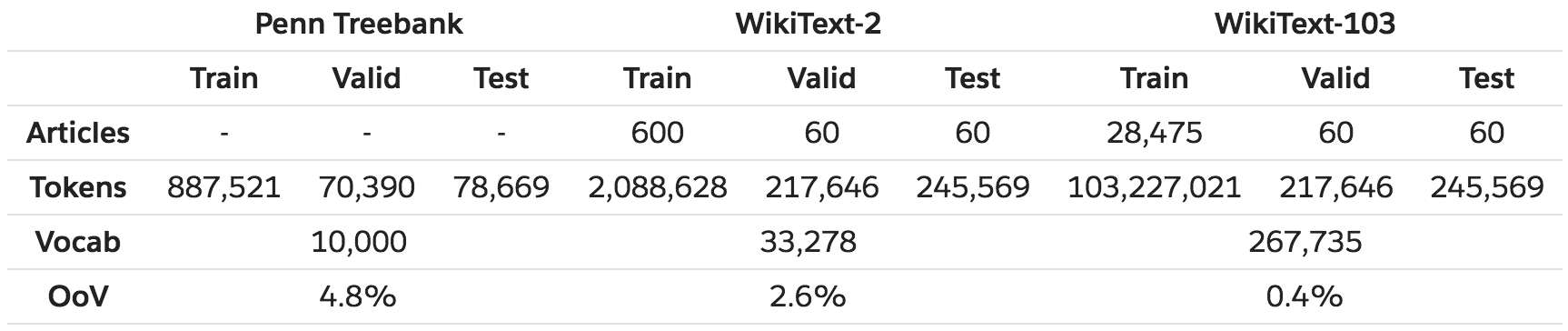
The WikiText language modeling dataset is a collection of over 100 million tokens extracted
from the set of verified Good and Featured articles on Wikipedia.
Compared to the preprocessed
version of Penn Treebank (PTB), WikiText-2 is over 2 times larger and WikiText-103 is over
110 times larger. The WikiText dataset also features a far larger vocabulary and retains the
original case, punctuation and numbers - all of which are removed in PTB. As it is composed
of full articles, the dataset is well suited for models that can take advantage of long term
dependencies.
In comparison to the Mikolov processed version of the Penn Treebank (PTB),
the WikiText datasets are larger. WikiText-2 aims to be of a similar size to the PTB while
WikiText-103 contains all articles extracted from Wikipedia. The WikiText datasets also retain
numbers (as opposed to replacing them with N), case (as opposed to all text being lowercased),
and punctuation (as opposed to stripping them out).
Data Collection
We selected articles only fitting the Good or Featured article criteria specified by editors
on Wikipedia. These articles have been reviewed by humans and are considered well written,
factually accurate, broad in coverage, neutralin point of view, and stable. This resulted in
23,805 Good articles and 4,790 Featured articles. The text for each article was extracted using
the Wikipedia API. Extracting the raw text from Wikipedia mark-up is nontrivial due to the
large number of macros in use. These macros are used extensively and include metric conversion,
abbreviations, language notation, and date handling.
Once extracted, specific sections which
primarily featured lists were removed by default. Other minor bugs, such assort keys and Edit
buttons that leaked in from the HTML, were also removed. Mathematical formulae and LaTeX code,
were replaced with¡´formula¡µtokens. Normalization and tokenization were performed using the
Moses tokenizer, slightly augmented to further split numbers (8,600¡ú8 @,@ 600) and with some
additional minor fixes. A vocab-ulary was constructed by discarding all words with a count
below 3. Words outside of the vocabulary were mapped to the¡´unk¡µtoken, also a part of the vocabulary.


- 分享你的想法
全部内容
数据使用声明:
- 1、该数据来自于互联网数据采集或服务商的提供,本平台为用户提供数据集的展示与浏览。
- 2、本平台仅作为数据集的基本信息展示、包括但不限于图像、文本、视频、音频等文件类型。
- 3、数据集基本信息来自数据原地址或数据提供方提供的信息,如数据集描述中有描述差异,请以数据原地址或服务商原地址为准。
- 1、本站中的所有数据集的版权都归属于原数据发布者或数据提供方所有。
- 1、如您需要转载本站数据,请保留原数据地址及相关版权声明。
- 1、如本站中的部分数据涉及侵权展示,请及时联系本站,我们会安排进行数据下线。
 VIP下载(最低0.24/天)
VIP下载(最低0.24/天) 1180浏览
1180浏览 0下载
0下载 0点赞
0点赞 收藏
收藏 分享
分享