



 已解决
已解决

|
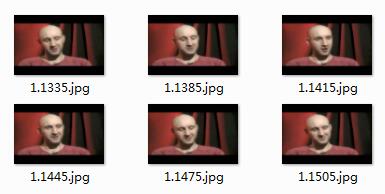
CMU-MIT CMU-MIT 是由卡内基梅隆大学和麻省理工学院一起收集的数据集,所有图片都是黑白的
gif
格式。里面包含
511
个闭合的人脸图像,其中
130
个是正面的人脸图像。图像如下图所示,没有找到官方链接,
Github
下载链接为
https://github.com/watersink/CMU-MIT
GENKI GENKI数据集是由加利福尼亚大学的机器概念实验室收集。该数据集包含GENKI-R2009a,GENKI-4K,GENKI-SZSL三个部分。GENKI-R2009a包含11159个图像,GENKI-4K包含4000个图像,分为“笑”和“不笑”两种,每个图片的人脸的尺度大小,姿势,光照变化,头的转动等都不一样,专门用于做笑脸识别。GENKI-SZSL包含3500个图像,这些图像包括广泛的背景,光照条件,地理位置,个人身份和种族等。图像如下图所示,下载链接为http://mplab.ucsd.edu,如果进不去可以,同样可以去下面的github下载,链接https://github.com/watersink/GENKI
IJB-A (IARPA JanusBenchmark A) IJB-A是一个用于人脸检测和识别的数据库,包含24327个图像和49759个人脸。图像如下图所示,需要邮箱申请相应帐号才可以下载,下载链接为http://www.nist.gov/itl/iad/ig/ijba_request.cfm
MALF (Multi-Attribute Labelled Faces) MALF
是为了细粒度的评估野外环境中人脸检测模型而设计的数据库。数据主要来源于
Internet
,包含
5250
个图像,
11931
个人脸。每一幅图像包含正方形边界框,俯仰、蜷缩等姿势等。该数据集忽略了小于
20*20
的人脸,大约
838
个人脸,占该数据集的
7%
。同时,该数据集还提供了性别,是否带眼镜,是否遮挡,是否是夸张的表情等信息。图像如下图所示,需要申请才可以得到官方的下载链接,链接为
http://www.cbsr.ia.ac.cn/faceevaluation/
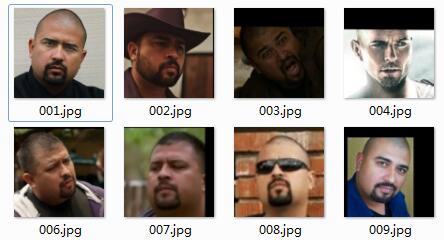
MegaFace MegaFace资料集包含一百万张图片,代表690000个独特的人。所有数据都是华盛顿大学从Flickr(雅虎旗下图片分享网站)组织收集的。这是第一个在一百万规模级别的面部识别算法测试基准。 现有脸部识别系统仍难以准确识别超过百万的数据量。为了比较现有公开脸部识别算法的准确度,华盛顿大学在去年年底开展了一个名为“MegaFace Challenge”的公开竞赛。这个项目旨在研究当数据库规模提升数个量级时,现有的脸部识别系统能否维持可靠的准确率。图像如下图所示,需要邮箱申请才可以下载,下载链接为http://megaface.cs.washington.edu/dataset/download.html
300W 300W数据集是由AFLW,AFW,Helen,IBUG,LFPW,LFW等数据集组成的数据库。 图像如下图所示,需要邮箱申请才可以下载,下载链接为
http://ibug.doc.ic.ac.uk/resources/300-W/
IMM Data Sets IMM人脸数据库包括了240张人脸图片和240个asf格式文件(可以用UltraEdit打开,记录了58个点的地标),共40个人(7女33男),每人6张人脸图片,每张人脸图片被标记了58个特征点。所有人都未戴眼镜,图像如下图所示,下载链接为http://www2.imm.dtu.dk/~aam/datasets/datasets.html
MUCT Data Sets
MUCT人脸数据库由3755个人脸图像组成,每个人脸图像有76个点的地标(landmark),图片为jpg格式,地标文件包含csv,rda,shape三种格式。该图像库在种族、关照、年龄等方面表现出更大的多样性。具体图像如下图所示,下载链接为 http://www.milbo.org/muct/
ORL (AT&T Dataset) ORL数据集是剑桥大学AT&T实验室收集的一个人脸数据集。包含了从1992.4到1994.4该实验室的成员。该数据集中图像分为40个不同的主题,每个主题包含10幅图像。对于其中的某些主题,图像是在不同的时间拍摄的。在关照,面部表情(张开眼睛,闭合眼睛,笑,非笑),面部细节(眼镜)等方面都变现出了差异性。所有图像都是以黑色均匀背景,并且从正面向上方向拍摄。 其中图片都是PGM格式,图像大小为92*102,包含256个灰色通道。具体图像如下图所示,下载链接为http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html VGG Face dataset 该数据集包含了2622个不同的人,每个人包含1000张图片,是一个训练人脸识别的大的数据集,官网提供了每个图片的URL,需要自己解析下载,当然有些链接是需要翻墙的,要不可能下载不全哦。 下载链接:http://www.robots.ox.ac.uk/~vgg/data/vgg_face/ CASIA WebFace Database 该数据集为中科院自动化所,李子青老师组开源的数据集,包含了10575类人,一共494414张图片,其中有3类人和lfw中的一样。该数据集主要用于人脸识别。图像都是著名电影中crop而出的,每个图片的大小都是250*250,每个类下面都有3张以上的图片,非常适合做人脸识别的训练。现在发paper比较一致的做法都是在该数据集上训练下,再在lfw数据集做个测试。需要邮箱申请,下载链接:http://www.cbsr.ia.ac.cn/english/CASIA-WebFace-Database.html CelebA(Large-scale CelebFaces Attributes dataset) 该数据集为香港中文大学汤晓鸥老师组开源的数据集,主要包含了5个关键点,40个属性值等,包含了202599张图片,图片都是高清的名人图片,可以用于人脸检测,5点训练,人脸头部姿势的训练等。下载链接:http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html YouTuBe Faces DB 该数据集主要用于非约束条件下的视频中人脸识别,姿势判定等。该数据集包含1595个不同人的3425个视频,平均每个人的类别包含了2.15个视频,每个类别最少包含48帧,最多包含6070帧,平均包含181.3帧。下载链接:http://www.cslab.openu.ac.il/agas/,或者,http://www.cslab.openu.ac.il/download/,如果没有效果,可以尝试filezilla下载, server:agas.openu.ac.il Path: /v/data9/cslab/wolftau/ filezilla模式设置为"Transfer mode" |








|
举报
2021-11-20 10:07
AFLW(Annotated Facial Landmarks in the Wild) AFLW人脸数据库是一个包括多姿态、多视角的大规模人脸数据库,而且每个人脸都被标注了21个特征点。此数据库信息量非常大,包括了各种姿态、表情、光照、种族等因素影响的图片。AFLW人脸数据库大约包括25000万已手工标注的人脸图片,其中59%为女性,41%为男性,大部分的图片都是彩色,只有少部分是灰色图片。该数据库非常适合用于人脸识别、人脸检测、人脸对齐等方面的研究,具有很高的研究价值。图像如下图所示,需要申请帐号才可以下载,下载链接为http://lrs.icg.tugraz.at/research/aflw/
|

|
举报
2021-11-20 10:08
LFW(Labeled Faces in the Wild) LFW是一个用于研究无约束的人脸识别的数据库。该数据集包含了从网络收集的13000张人脸图像,每张图像都以被拍摄的人名命名。其中,有1680个人有两个或两个以上不同的照片。这些数据集唯一的限制就是它们可以被经典的Viola-Jones检测器检测到(a hummor)。图像如下图所示,下载链接为http://vis-www.cs.umass.edu/lfw/index.html#download
|

|
举报
2021-11-20 10:08
AFW(Annotated Faces in the Wild) AFW数据集是使用Flickr(雅虎旗下图片分享网站)图像建立的人脸图像库,包含205个图像,其中有473个标记的人脸。对于每一个人脸都包含一个长方形边界框,6个地标和相关的姿势角度。数据库虽然不大,额外的好处是作者给出了其2012 CVPR的论文和程序以及训练好的模型。图像如下图所示,下载链接为http://www.ics.uci.edu/~xzhu/face/ |

|
举报
2021-11-20 10:08
FDDB(Face Detection Data Set and Benchmark) FDDB数据集主要用于约束人脸检测研究,该数据集选取野外环境中拍摄的2845个图像,从中选择5171个人脸图像。是一个被广泛使用的权威的人脸检测平台。图像如下图所示,下载链接为http://vis-www.cs.umass.edu/fddb/
|

|
举报
2021-11-20 10:09
WIDER FACE WIDER FACE是香港中文大学的一个提供更广泛人脸数据的人脸检测基准数据集,由YangShuo, Luo Ping ,Loy ,Chen Change ,Tang Xiaoou收集。它包含32203个图像和393703个人脸图像,在尺度,姿势,闭塞,表达,装扮,关照等方面表现出了大的变化。WIDER FACE是基于61个事件类别组织的,对于每一个事件类别,选取其中的40%作为训练集,10%用于交叉验证(cross validation),50%作为测试集。和PASCAL VOC数据集一样,该数据集也采用相同的指标。和MALF和Caltech数据集一样,对于测试图像并没有提供相应的背景边界框。图像如下图所示,下载链接为http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/
|
