



大模型训练语料篇—已有大规模数据集: C4 / Pile / ROOTS / Wudao
前言
大模型的训练,大规模的语料是很重要的,这篇博文跟大家讨论下目前比较出名的大规模语料,讨论它们的来源/多样性/清洗方式等作为参考
C4
2021 EMNLP,T5的训练语料,2021年 4 月
数据清洗 URL: https://github.com/google-research/text-to-text-transfer-transformer/tree/main/t5/data
记录问题 URL: https://github.com/allenai/c4-documentation
下载 URL: https://github.com/allenai/allennlp/discussions/5056
检索 URL: https://c4-search.apps.allenai.org/
Paper: https://arxiv.org/pdf/2104.08758.pdf
大型语言模型在许多自然语言处理任务上取得了显著进展,研究人员正在转向越来越大的文本语料库进行训练。一些最大的语料库是通过从互联网上爬取大量文本而创建的,并且通常只有很少的文档说明。在这项工作中,作者为巨型爬虫数据 Common Crawl 做清洗后得到的语料库 C4 提供了一些详细的文档文档,该数据集是通过对 Common Crawl 的一个快照应用一组过滤器创建的。作者首先调查数据的来源,发现了 Common crawl 大量意想不到的来源,例如专利和美国军事网站的文本。然后作者探索文本本身的内容,发现 Common Crawl 里有机器生成的文本(例如来自机器翻译系统)和其他基准自然语言处理数据集的评估示例。为了了解应用于创建此数据集的过滤器的影响,评估了被删除的文本,并显示黑名单过滤器不成比例地删除了有关少数族裔的文本。最后,作者提出了一些关于如何从互联网爬取并记录数据集的建议。
C4是可用的最大语言数据集之一,收集了来自互联网上超过3.65亿个域的超过1560亿个token。
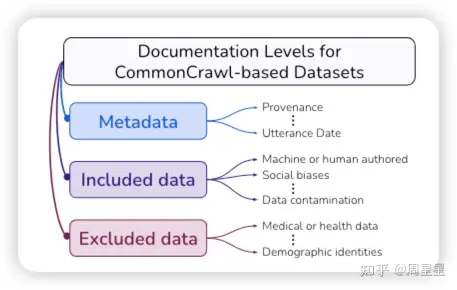
C4是通过获取 Common Crawl 的2019年4月快照并应用多个过滤器来创建的,旨在删除非自然英语的文本。这包括过滤不以终端标点符号结尾或少于三个单词的行,丢弃少于五个句子或包含Lorem ipsum占位符文本的文档,并删除包含“Dirty,Naughty,Obscene或Otherwise Bad Words清单”上任何单词的文档。另外,还使用 langdetect8 删除未被分类为英语且概率至少为0.99的文档,因此C4主要由英文文本组成。将这个“清洗”版本的C4(通过应用所有过滤器创建)称为C4.EN。为了简洁起见,作者建议读者参考Raffel等人(2020)提供的完整过滤器列表。
除了C4.EN之外,作者还托管着“未清理”版本(C4.EN.NOCLEAN),它是被确定为英语的Common Crawl快照(没有应用其他过滤器),以及C4.EN.NOBLOCKLIST,它与C4.EN相同,但不会过滤掉包含来自单词屏蔽列表的标记的文档(有关更多详细信息,请参见§5)。表1包含三个语料库的一些统计数据。
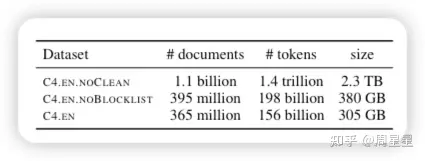
以下是作者建议大家在做大规模预训练时要记录的文档信息
元数据
互联网域名/网站、言论日期、地理位置
包括的数据
机器生成的文本、基准数据污染、C4.EN中的人口统计偏差
排除的数据(要明白过滤器的危害)
描述被排除的文档、哪些人口统计身份被排除、哪些人的英语被包括在内
ROOTS
NeurIPS 2022,BLOOM 的训练语聊
下载 URL: https://huggingface.co/bigscience-data
清洗 URL: https://github.com/bigscience-workshop/data-preparation
the Responsible Open-science Open-collaboration Text Sources (ROOTS)
一个1.6TB的数据集跨越了59种语言(46种自然语言,13种编程语言),用于训练拥有1760亿个参数的BigScience大型公开科学多语言开放访问(BLOOM)语言模型。(BigScience Workshop, 2022)
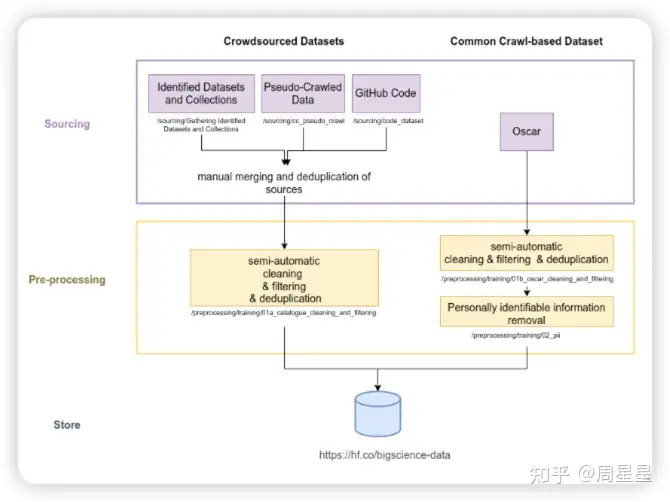
62%的文本来自社区选择和记录的语言数据源列表,另外38%的文本来自经过预处理的网络爬取数据集OSCAR, 并通过母语人士的帮助进行了过滤
62% 通过社区收集得到
主要包括三个来源:已整理好的数据集,如一些已有的 NLP 数据集等
伪爬虫数据集,部分志愿者提交的网站,但还没包括内容,这时要利用 url 去 Common Crawl 的快照中解析对应的内容
GitHub Code
三部分得到后要做一个融合和去重。后面还接了一些手工的提升方法以提高数据集的质量。
38% 从OSCAR 清洗得到
数据清洗和过滤
太高的字符重复或单词重复作为重复内容的度量标准。
过高的特殊字符比例以去除页面代码或爬行工件。
关闭类单词的比率不足以过滤出SEO页面。
过高的标志词比例以过滤出色情垃圾。我们要求贡献者根据这个标准量身定制他们语言中的单词列表(而不是与性有关的通用术语),并偏向于高精度。
过高的困惑度值以过滤非自然语言。
单词数量不足,因为LLM训练需要广泛的上下文大小。
去重:采用 simhash 去重,对长文本进行特殊处理
去除个人信息
Pile
2020年,825G的语料
Url (处理代码): https://github.com/EleutherAI/the-pile
Paper: https://arxiv.org/abs/2101.00027
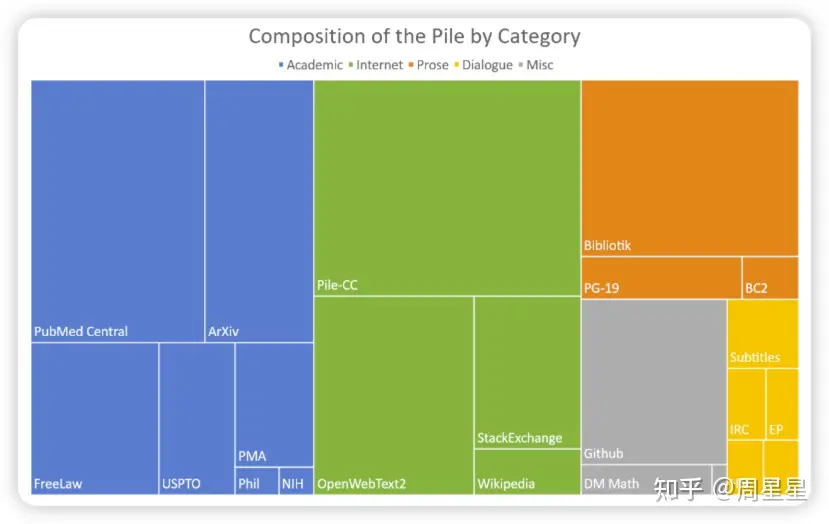
最近的工作表明,增加训练数据集的多样性可以提高大规模语言模型的跨领域知识和下游泛化能力。基于此,作者介绍了Pile:一个面向训练大规模语言模型的825 GiB英语文本语料库。Pile由22个多样化的高质量子集构成,包括现有的和新构建的子集,许多子集来自学术或专业来源。作者对GPT-2和GPT-3在Pile上的未调优性能进行了评估,结果显示这些模型在许多组成部分上都存在困难,比如学术写作。相反,使用Pile训练的模型在Pile的所有组成部分上都比Raw CC和CC-100都有显著的改进,并提高了下游评估的性能。通过深入的探索性分析,作者记录了数据的一些潜在问题,供潜在用户参考。作者公开了其构建所使用的代码。
这些结果表明,通过混合大量较小、高质量、多样化的数据集,作者可以提高模型的跨领域知识和下游泛化能力,相比于仅在少数数据源上训练的模型。
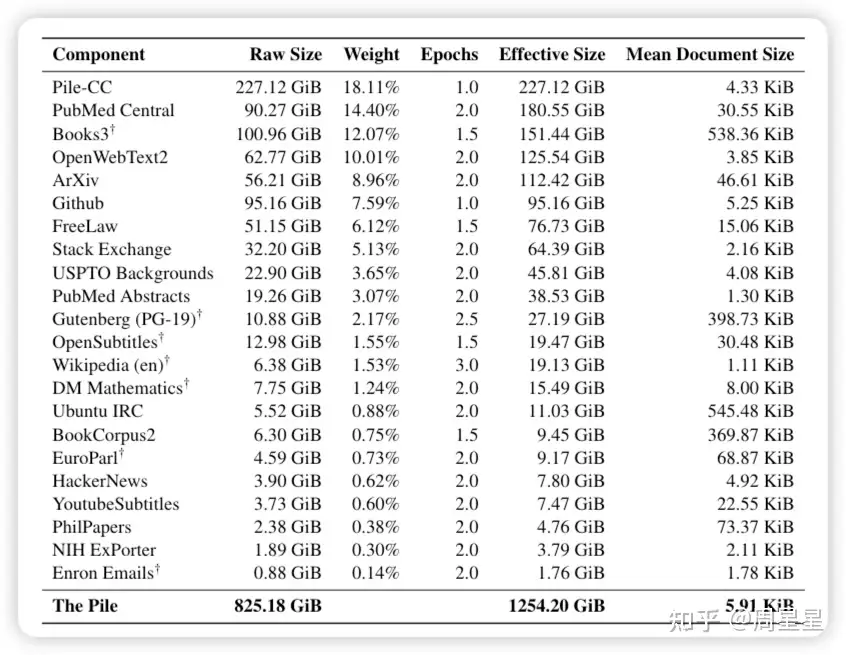
网络数据
Pile-CC: 使用 jusText提取 Common Crawl。过滤实现使用针对 OpenWebText2 数据集进行训练的 fasttext 分类器。仅处理可用 Common Crawl 数据的一小部分;我们将 2013 年至 2020 年的 url 列表分成 3679 个块,然后处理 22 个随机块。
OpenWebText2⭐️:是 Pile 提出的信数据集,从所有截至2020年4月的 Reddit 提交中提取了URL及其相关的元数据。URL进行了去重,每个唯一的URL都具有相关提交元数据列表和聚合分数。聚合分数小于 3 的 URL 被删除。然后使用 Newspaper 对链接进行了爬取和处理。使用 DataSketch 库的内存 MinHashLSH 在文档级别执行了去重操作。生成了过滤后和原始版本,原始版本仅通过URL进行了去重。过滤版本包含了17103059个文档的65。86GB未压缩文本。原始版本更大,包含了69547149个文档的193.89GB未压缩文本。
Stack Exchange⭐️:来自问答网站 stackexchange,每个问题只保留回答点赞数大于三的前三个回答,并组织成 QA 问答对的形式,最终得到 365 个类别下的15622475篇文档。
Wikipedia (English): 英文 wiki 数据集,使用TensorFlow数据集中的wikipedia/20200301.en数据集。在每篇文章的正文前加上标题,中间用两个换行符隔开。
学术数据
PubMed Central⭐️:PubMed Central(PMC)是美国国家生物技术信息中心(NCBI)运营的生物医学文章在线存储库PubMed的子集,为近500万篇出版物提供开放的全文访问。
ArXiv⭐️:通过arXiv的S3批量源文件访问下载了截至2020年7月的所有论文的TEX源代码,并使用pandoc 1.19.2.4将这些源文件转换为Markdown。在转换过程中出现错误的论文被丢弃。这一过程产生了总共1,264,405篇论文。
FreeLaw⭐️: 法院意见数据。
USPTO Backgrounds⭐️: 专利相关的数据集。
PubMed Abstracts⭐️: 生物医学领域的标题和摘要。
PhilPapers⭐️: 哲学相关的论文。
NIH Grand ABstracts: ExPORTER⭐️: 美国国立卫生研究院(NIH)经费数据库。
书籍数据
Books3:Books3是一个图书数据集,包含有小说和非小说,相比于 BookCorpus2 大了一个数量级。
Project Gutenberg: 西方古典文学的数据集,风格与线代文学很不同。
BookCorpus2⭐️: 是 BookCorpus 的扩充,有 17868 本书,由于 BookCorpus2 的都是没出版的,因此不会跟 Books3 和 Project Gutenberg 的重叠。
对话数据
OpenSubtitles: 电视和电影的英文字幕。
Ubuntu IRC⭐️: Ubuntu IRC 数据集是从 Freenode IRC 聊天服务器上所有 Ubuntu 相关频道的公开聊天记录中派生出来的。聊天记录数据6提供了一个建模实时人类交互的机会,这种交互具有其他社交媒体模式通常不具备的自发性。
EuroParl: 一个多语言平行语料库,最初是为了机器翻译而引入的。
YouTube Subtitles⭐️: YouTube字幕数据集是从YouTube上人工生成的封闭字幕中收集的文本平行语料库。除了提供多语言数据外,YouTube字幕还是教育内容、流行文化和自然对话的来源。
Hacker News⭐️: 用户提交的文章被定义为“满足一个人的知识好奇心的任何事物”,但提交的文章往往集中在计算机科学和创业主题上。用户可以评论提交的故事,导致评论树讨论和批评提交的故事。我们会抓取、解析和包含这些评论树,因为作者相信它们提供了高质量的讨论和辩论的细分主题。
其它数据
Github⭐️:github 的代码数据,用两步进行收集1. 收集所需仓库和其元数据的列表 2. 从每个仓库中提取用于语言建模的所有文本数据。
DeepMind Mathematics: 由代数、算术、微积分、数论和概率等主题的数学问题集合组成。
Enron Emails: 电子邮件数据集。
WuDaoCorpora
2021年
url: https://data.baai.ac.cn/details/WuDaoCorporaText
paper: https://www.sciencedirect.com/science/article/pii/S2666651021000152
完整版:3TB training data and 1.08T trillion Chinese characters,包含有 822 million Web pages
有‘content’字段
有’index’字段:which field it belongs
base 版:200G & 72 billion Chinese characters
悟道使用30亿个网页作为原始数据源,并从中提取高文本密度的文本内容。提取的文本包含许多额外的字符,损害内容的完整性和流畅性,例如网页标识符、异常符号和乱码。此外,从某些网页提取的文本内容中存在敏感信息和个人隐私信息,这可能会导致训练模型中出现不良趋势和信息泄露问题。为了解决这些问题,在数据清理过程中,作者开发了一套处理流程,以提高语料库的质量。
以下是数据清理的具体步骤:
在文本提取之前,会评估每个数据源的质量,并忽略文本密度低于70%的网页。
由于网页文本转载现象普遍存在,使用simhash算法删除重复内容。
少量文字的网页通常意味着它们不包含有意义的句子。这些网页不适合用于训练语言模型。如果一个网页包含少于10个汉字,会忽略它。
脏话、煽动性评论和其他非法内容等敏感信息会对建设和谐、积极的社会环境产生不利影响。排除包含上述内容的网页。
为了最大程度地保护每个人的隐私安全,使用正则表达式匹配私人信息(如身份证号码、电话号码、QQ号码、电子邮件地址等),并从数据集中删除它们。
不完整的句子在模型训练中可能会出现问题。使用标点符号(如句号、感叹号、问号、省略号)来分隔提取出的文本,并删除最后一段,有时最后一段可能是不完整的。
由于某些网页违反了W3C标准,从这些网页提取的文本可能会乱码。为了排除语料库中的乱码内容,我们过滤掉高频乱码词汇的网页,并使用解码测试进行二次检查。
由于简体和繁体中都有汉字,将这些繁体汉字转换为简体汉字,以使的语料库中字符格式统一。
为了保证提取的文本流畅,从网页中删除那些异常符号(如表情符号、标志等)。
为了避免的数据集中存在过长的非中文内容,我们排除那些包含超过十个连续非中文字符的网页。
由于网页标识符(如HTML、层叠样式表(CSS)和Javascript)对语言模型训练没有帮助,从提取的文本中删除它们。
由于用空格分隔两个汉字是不必要的,删除每个句子中的所有空格,以规范化的语料库。
其它数据源
https://github.com/thunlp/THUCTC:THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。我们在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐
https://github.com/CLUEbenchmark/CLUECorpus2020:通过对Common Crawl的中文部分进行语料清洗,最终得到100GB的高质量中文预训练语料
https://github.com/togethercomputer/RedPajama-Data:用于重现LLama训练数据集的开源数据集

 条内容
条内容