



用高斯混合模型(GMM)的最大期望(EM)聚类
K-Means的缺点在于对聚类中心均值的简单使用。下面的图中的两个圆如果使用K-Means则不能作出正确的类的判断。同样的,如果数据集中的点类似下图中曲线的情况也是不能正确分类的。

使用高斯混合模型(GMM)做聚类首先假设数据点是呈高斯分布的,相对应K-Means假设数据点是圆形的,高斯分布(椭圆形)给出了更多的可能性。我们有两个参数来描述簇的形状:均值和标准差。所以这些簇可以采取任何形状的椭圆形,因为在x,y方向上都有标准差。因此,每个高斯分布被分配给单个簇。
所以要做聚类首先应该找到数据集的均值和标准差,我们将采用一个叫做最大期望(EM)的优化算法。下图演示了使用GMMs进行最大期望的聚类过程。
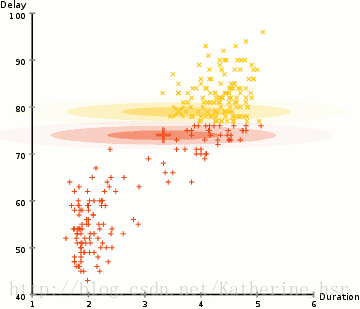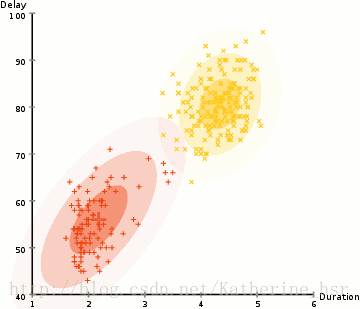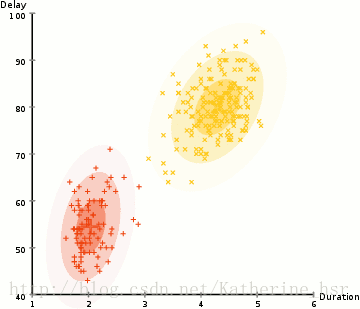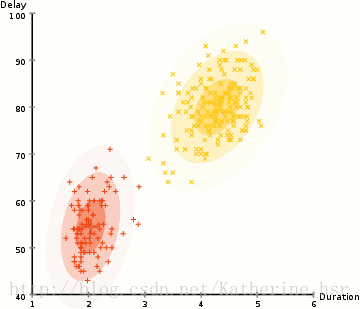
具体步骤:
1. 选择簇的数量(与K-Means类似)并随机初始化每个簇的高斯分布参数(均值和方差)。也可以先观察数据给出一个相对精确的均值和方差。
2. 给定每个簇的高斯分布,计算每个数据点属于每个簇的概率。一个点越靠近高斯分布的中心就越可能属于该簇。
3. 基于这些概率我们计算高斯分布参数使得数据点的概率最大化,可以使用数据点概率的加权来计算这些新的参数,权重就是数据点属于该簇的概率。
4. 重复迭代2和3直到在迭代中的变化不大。
GMMs的优点:(1)GMMs使用均值和标准差,簇可以呈现出椭圆形而不是仅仅限制于圆形。K-Means是GMMs的一个特殊情况,是方差在所有维度上都接近于0时簇就会呈现出圆形。
(2)GMMs是使用概率,所有一个数据点可以属于多个簇。例如数据点X可以有百分之20的概率属于A簇,百分之80的概率属于B簇。也就是说GMMs可以支持混合资格。
https://blog.csdn.net/weixin_42056745/article/details/101287231

 条内容
条内容