


小小程序员
2021-05-12 16:56:34

层次聚类算法
层次聚类算法实际上分为两类:自上而下或自下而上。自下而上的算法在一开始就将每个数据点视为一个单一的聚类,然后依次合并(或聚集)类,直到所有类合并成一个包含所有数据点的单一聚类。因此,自下而上的层次聚类称为合成聚类或HAC。聚类的层次结构用一棵树(或树状图)表示。树的根是收集所有样本的唯一聚类,而叶子是只有一个样本的聚类。在继续学习算法步骤之前,先查看下面的图表。
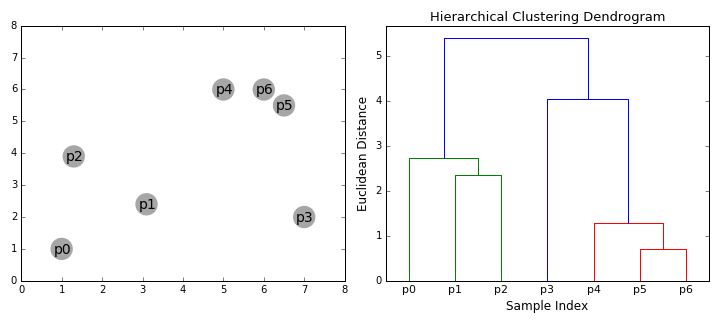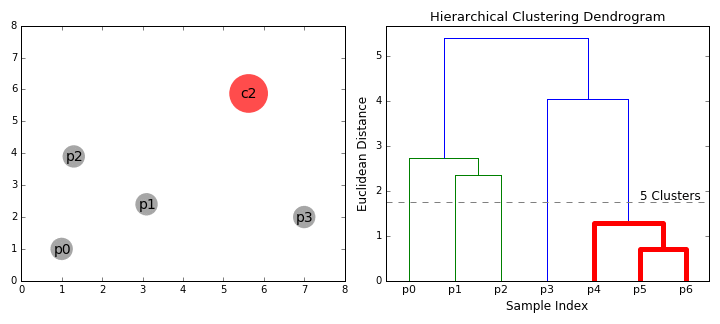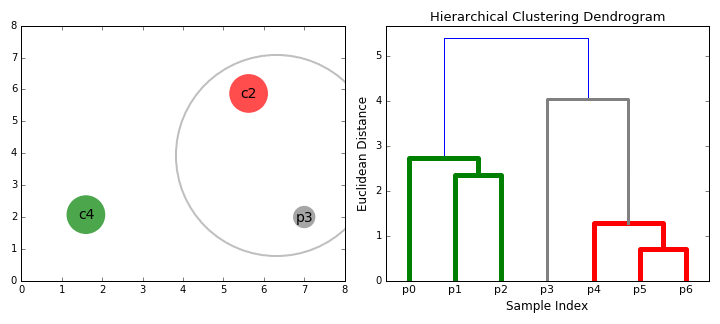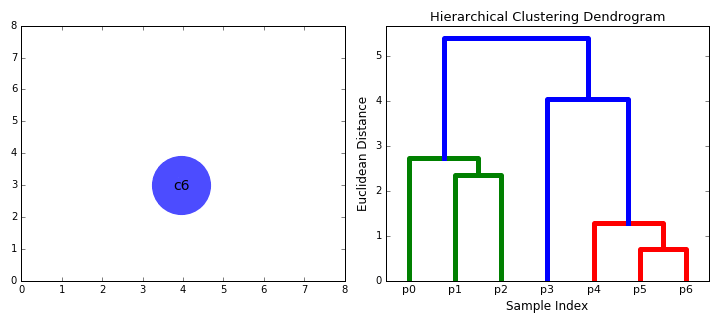
合成聚类
1.我们首先将每个数据点作为一个单独的聚类进行处理。如果我们的数据集有X个数据点,那么我们就有了X个聚类。然后我们选择一个度量两个聚类之间距离的距离度量。作为一个示例,我们将使用平均连接(average linkage)聚类,它定义了两个聚类之间的距离,即第一个聚类中的数据点和第二个聚类中的数据点之间的平均距离。
2.在每次迭代中,我们将两个聚类合并为一个。将两个聚类合并为具有最小平均连接的组。比如说根据我们选择的距离度量,这两个聚类之间的距离最小,因此是最相似的,应该组合在一起。
3.重复步骤2直到我们到达树的根。我们只有一个包含所有数据点的聚类。通过这种方式,我们可以选择最终需要多少个聚类,只需选择何时停止合并聚类,也就是我们停止建造这棵树的时候!
层次聚类算法不要求我们指定聚类的数量,我们甚至可以选择哪个聚类看起来最好。此外,该算法对距离度量的选择不敏感;它们的工作方式都很好,而对于其他聚类算法,距离度量的选择是至关重要的。层次聚类方法的一个特别好的用例是,当底层数据具有层次结构时,你可以恢复层次结构;而其他的聚类算法无法做到这一点。层次聚类的优点是以低效率为代价的,因为它具有O(n³)的时间复杂度,与K-Means和高斯混合模型的线性复杂度不同。

 条内容
条内容